

大語言模型競技場 https://lmarena.ai/
Overview Leaderboard | LMArena
LiveBench 2025/4/25

以下是針對 2025 年 LLM 智能模型 IQ 排行榜所撰寫的專業文章,可用於講座簡報、內部教育訓練或產業趨勢觀察:
2025 年大型語言模型(LLM)IQ排行榜分析報告
— OpenAI o3 領銜,AI 智能競逐進入高階推理時代
在生成式 AI 技術快速進化之際,如何衡量大型語言模型(LLM)的「智慧水平」逐漸成為產業關注焦點。根據知名平台 TrackingAI.org 與 Mensa Norway 測驗標準,2025 年最新發布的 IQ 排行榜,為我們揭示了各主流模型在圖形邏輯與推理能力上的真實實力。
本報告將根據該測驗結果,深入解析前十名模型的表現與產業意涵。
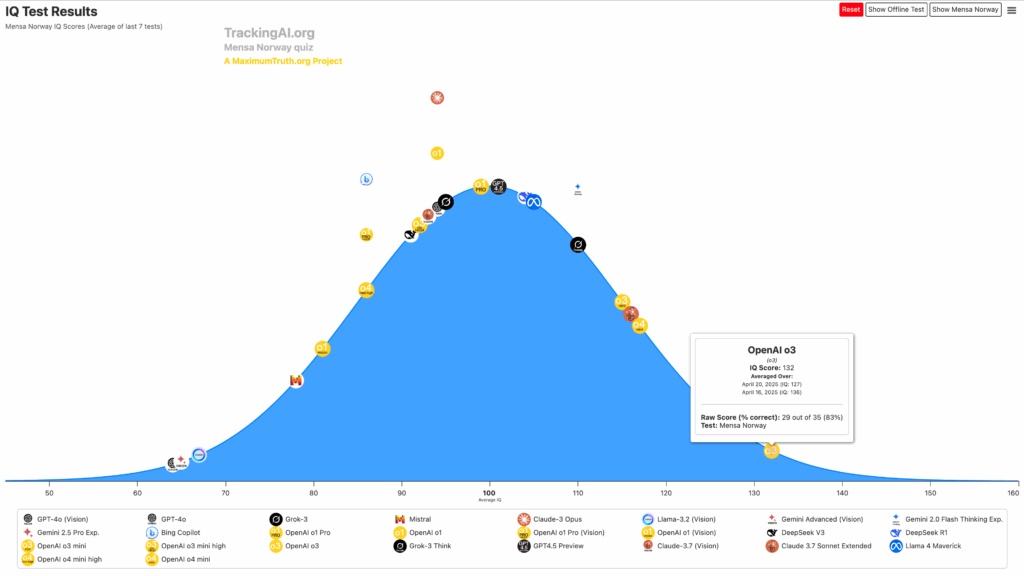
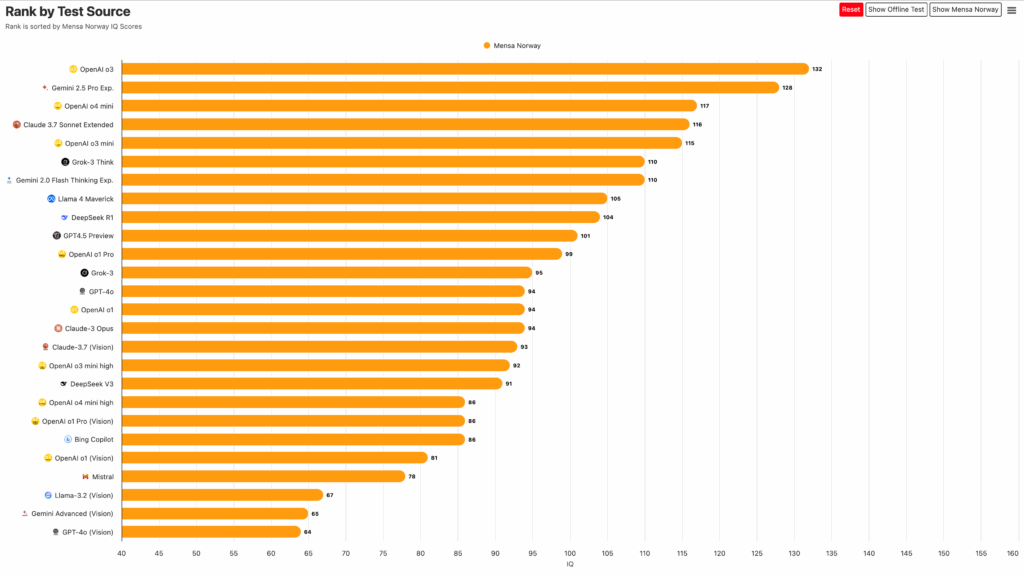
📊 前十名模型總覽
| 排名 | 模型名稱 | 開發者 | IQ 分數 | 關鍵特色 |
|---|---|---|---|---|
| 1 | o3 | OpenAI | 136 | 邏輯推理領先全場,86% 答對率 |
| 2 | o1 | OpenAI | 133 | 高穩定性與深度推理能力 |
| 3 | Gemini 2.5 Pro | Google DeepMind | 130 | 多模態理解能力強,語圖整合佳 |
| 4 | Claude 3.5 Sonnet | Anthropic | 128 | 語言理解優異,推理兼具 |
| 5 | Qwen 2.5-Max | Alibaba | 127 | 中文推理特化,在東亞語境表現強勁 |
| 6 | DeepSeek R1 | DeepSeek | 126 | 領先的開源模型,推理表現亮眼 |
| 7 | LLaMA 3.1 405B | Meta | 125 | 社群支持廣泛,生成與推理兼備 |
| 8 | Grok-3 | xAI | 124 | 架構創新,語言生成能力佳 |
| 9 | Mistral Large 2 | Mistral AI | 123 | 在數據壓縮與運算效率中取平衡 |
| 10 | GPT-4.5 | OpenAI | 122 | 全方位發展,語境理解靈活 |
📌 三大觀察亮點
1. OpenAI 強勢佔據領先地位
在前十名中,OpenAI 以三款模型(o3、o1、GPT-4.5)上榜,尤其 o3 更以 IQ 136 的成績榮登榜首。這顯示出 OpenAI 在邏輯推理、長文本處理與模型訓練策略上的深厚功力。
2. 開源模型實力不容小覷
DeepSeek R1 與 LLaMA 3.1 等開源系統進入前段班,代表 AI 開源生態圈已不再只是「平價選擇」,而是技術與實務應用並進的關鍵力量。
3. 語境與模態整合成關鍵趨勢
Google Gemini、Claude、Qwen 等模型展示出強大的「語圖整合」、「語言多樣性理解」能力,預示未來 LLM 將持續從純語言邏輯,邁向多模態推理 + 語境適應的全面能力競賽。
🔍 背後測驗方法解析:Mensa Norway 測驗
- 測驗類型:圖形邏輯 IQ 類題型(35 題)
- 評估能力:圖形推理、模式識別、抽象邏輯
- 模型表現數據:採「平均答對率」、「累計測試次數」雙指標進行排序
特別說明:該測驗為通用認知測驗,不涉及語料庫記憶,有助於檢視「泛化推理」能力。
🔮 實務應用建議:如何根據 IQ 模型挑選 AI 工具?
| 應用場景 | 建議模型 | 原因 |
|---|---|---|
| 複雜邏輯分析 | o3、Claude 3.5 | 邏輯架構與細節推演精準 |
| 多語言內容生成 | Qwen、Gemini | 對中文與多模態內容處理更具優勢 |
| 教學與知識問答 | GPT-4.5、LLaMA | 應對廣泛問題具備穩定的泛用性 |
| 成本效益型應用 | DeepSeek、Mistral | 高效能開源架構,適合 SME 或獨立開發者採用 |
✨ 結語:智能時代的模型選擇思維
2025 年的 IQ 排行榜,不僅是一次技術實力的公開賽,更揭示了 AI 模型能力的多維進化方向。從邏輯推理、圖像理解、到語言多樣性與開源活力,這場競爭已進入全面智能的黃金時代。
對於企業與教育機構而言,與其追逐「最新最大」,不如深入理解模型特性與使用場景的契合度,才是真正實現 AI 效益最大化的關鍵。
延伸閱讀:
TrackingAI.org 是一個由資深記者 Maxim Lott 所創建的網站,旨在每日自動化追蹤並分析主流人工智慧(AI)聊天機器人的政治傾向和智力測驗表現。這個平台對於企業領導者、數位轉型專家以及 AI 開發者而言,是一個極具價值的工具,有助於評估 AI 模型的中立性與一致性。
—
🎯 核心功能與應用價值
1. 政治傾向監測TrackingAI.org 每日讓 16 個主流 AI 模型(如 ChatGPT、Claude、Bard 等)回答 62 題的政治羅盤測驗(Political Compass Test),並將其結果視覺化呈現這些測驗涵蓋經濟與社會議題,協助使用者了解各 AI 模型的政治立場
截至 2023 年,觀察顯示多數主流 AI 模型在經濟議題上偏向左派,在社會議題上則較為自由主義例如,Claude 被認為是較為中立的模型,而 Google 的 Bard 則被評為偏向極左
2. 智力測驗評估除了政治測驗外,TrackingAI.org 也讓 AI 模型參與 IQ 測驗,並將結果與人類標準進行比較這些測驗包括 Mensa Norway 的題目,並針對視覺模型提供圖片題目
3. 完整資料庫與透明性網站提供每個 AI 模型對每一道題目的原始回答,並建立可搜尋的資料庫這種透明性有助於研究人員、開發者和使用者深入了解 AI 模型的思維模式與潛在偏見
—
🧭 策略性意涵與應用建議
1. 選擇適合的 AI 工具
對於企業而言,了解各 AI 模型的政治傾向有助於選擇最符合組織價值觀的工具,避免在敏感議題上產生不必要的風。
2. 提升 AI 模型的中立性
AI 開發者可利用 TrackingAI.org 的數據,持續監控模型的偏向,並透過調整訓練資料或人類反饋機制,提升模型的中立性與多元。
3. 教育與培訓資源
對於教育機構與培訓單位,這個平台提供了豐富的案例與數據,協助學生與從業人員理解 AI 偏見的形成原因與影響,培養批判性思。
—
🔗 延伸閱讀與資源
– TrackingAI.org 官方網站:https://trackingai.og/
– 創辦人 Maxim Lott 的 Substack:https://maximumtruth.substack.cm/
– 政治羅盤測驗(Political Compass Test):https://www.politicalcompass.org/tst
GPT-o3/Gemini2.5/Claude3.7/Grok3横评,o3竟然不是最强的? – YouTube




