來源:Sora

If you think OpenAI Sora is a creative toy like DALLE, … think again. Sora is a data-driven physics engine. It is a simulation of many worlds, real or fantastical. The simulator learns intricate rendering, "intuitive" physics, long-horizon reasoning, and semantic grounding, all… pic.twitter.com/pRuiXhUqYR
— Jim Fan (@DrJimFan) February 15, 2024
美國時間2月15日,全球頂尖人工智能創業公司OpenAI驚喜發布了其最新的文生視頻大模型Sora。該模型展示的效果令人嘆為觀止,再次確立了OpenAI在生成式人工智能領域的領先地位。Sora模型為理解與模擬現實世界提供了堅實基礎,標誌著向通用人工智能(AGI)目標邁進的重要里程碑。
儘管ChatGPT在過去兩年中以其文字處理能力大受歡迎,但對於真實環境的理解仍有所欠缺。Sora模型展現了對空間及物體間物理關係的準確理解,這是達成AGI目標的一大進步。OpenAI公布的多個視頻演示,展示了其與真實世界場景幾乎無差異的生成能力,特別是物體間的真實物理互動,如狗在雪地中的玩耍,展現了模型對現實世界理解和模擬的基礎。
Sora模型能通過文字生成真實與想象的場景,並能生成長達一分鐘的視頻。它能創建包含多個人物、特定動作、精確物體細節和背景的複雜場景。此外,Sora模型還能基於靜態圖片生成視頻,並在已有視頻中插入圖像帧,顯示了其驚人的生成效果,如行人在日本街頭行走、狗在雪地玩耍等豐富場景。
Sora模型的技術背景基於擴散模型,從類似靜態噪聲的視頻開始,逐步去除噪聲生成視頻。模型使用了Transformer架構,提高了擴展性能。Sora在訓練階段將視頻和圖像拆解為更小的數據單元集合,稱為“補丁”,這使得模型能在更廣泛的視覺數據上進行訓練。
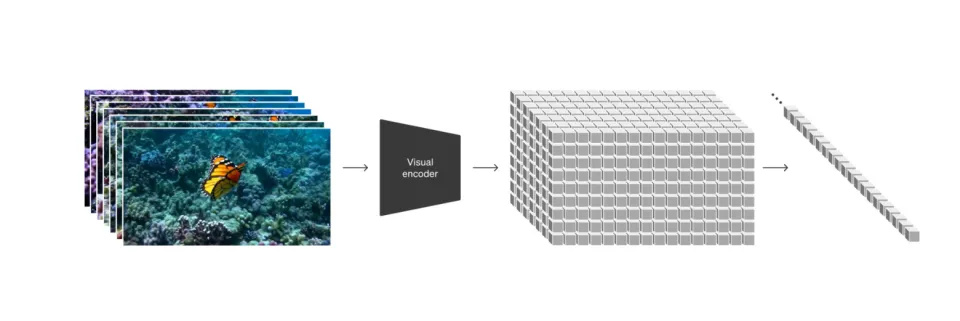
Sora不僅能生成視頻,還能生成不同尺寸的圖片,最大分辨率達到2048×2048。OpenAI指出,Sora模型在訓練過程中展現了一定的涌現能力,能夠模擬人、動物和環境在真實物理世界中的互動關係。儘管Sora展現了驚人的能力,但仍存在局限性,如不能準確模擬玻璃破碎等物理特性。

Sora的推出不僅展示了OpenAI的技術實力,也進一步證明了其朝向通用人工智能(AGI)目標的堅定步伐。從ChatGPT到Dall-E,再到現在的Sora,OpenAI正沿著從文字到多模態的過渡路徑穩步前進,不斷推動生成式人工智能領域的發展。