
Deepseek NSA — 論文解讀。在 groq 3 之後它們放了這篇 https://arxiv.org/pdf/2502.11089v1
這篇論文 Deepseek NSA 的解讀如下,核心亮點在於提出了一種創新的「原生稀疏注意力」(Native Sparse Attention, NSA)機制,徹底改善大模型處理超長文本的效率與性能。以下是繁體中文的詳細分析:
核心突破點
1. 高效處理超長文本,突破計算瓶頸
- 當前主流大模型(如 GPT-4、Gemini)在處理數萬至數十萬 tokens 的長文本時,因傳統注意力機制計算量暴增,導致速度極慢且成本高昂。
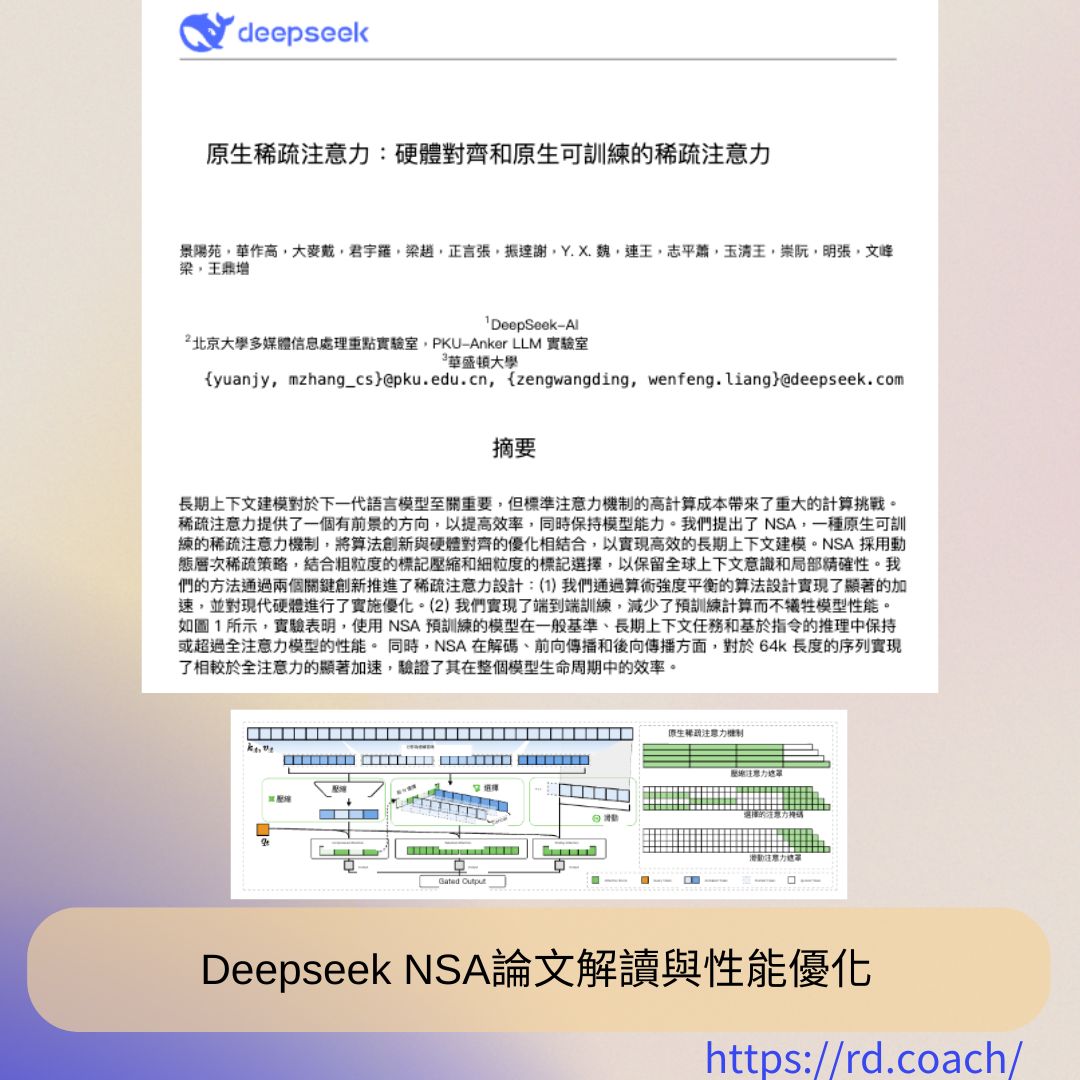
- NSA 的設計關鍵在於 分層稀疏注意力:
- 粗粒度壓縮:將文本分割為區塊(block),先對區塊級別進行注意力計算,篩選重要區塊。
- 細粒度聚焦:對關鍵區塊內的 tokens 進行精細化注意力計算。
- 滑動窗口機制:保留局部上下文連續性,避免短期記憶遺失。
- 效果:計算量大幅降低,長文本處理流暢無卡頓。
2. 訓練與推理雙重加速
- 過往稀疏注意力方案多僅優化推理階段,訓練時仍須使用全注意力(Full Attention),導致訓練成本未降低。
- NSA 從訓練階段即採用稀疏注意力,實現端到端效率提升:
- 訓練階段:顯存消耗降低,可支援更長序列的訓練任務。
- 推理階段:速度提升達 11.6 倍,顯著減少響應時間。
3. 硬體層級優化,理論與實務兼顧
- 多數稀疏注意力方法雖理論計算量低,但實際在 GPU 上因記憶體存取效率差,加速效果有限。
- NSA 針對 GPU 架構(如 NVIDIA A100)進行底層計算優化,確保實際運行效率。
實驗數據:
- 64k tokens 長文本場景:
- 推理加速 11.6×
- 前向傳播加速 9.0×
- 反向傳播加速 6.0×
- 效能直接超越 FlashAttention 2,成為「省時省錢」的新標竿。
4. 模型性能不妥協,反而更強
- 傳統稀疏方法常犧牲模型表現以換取效率,NSA 則在關鍵任務中表現更優:
- 邏輯推理:如數學問題(GSM8K)準確率提升。
- 程式碼生成:HumanEval 測試表現超越全注意力模型。
- 長文本問答:LongBench 數據集上回答品質更佳。
結論:NSA 非「以性能換速度」,而是「效率與能力雙贏」。
5. 顛覆傳統稀疏方法,開創新範式
- 舊有稀疏注意力方案的局限:
- 推理加速不顯著:因硬體適配差,實際加速有限。
- 無法應用於訓練:訓練階段仍需全注意力計算。
- NSA 從算法設計到硬體適配全面革新,解決上述痛點,成為長文本處理的實用方案。
總結
論文的核心價值在於:
✅ 徹底解決長文本計算瓶頸:讓模型處理數十萬 tokens 如行雲流水。
✅ 全流程加速:訓練與推理階段均顯著降低資源消耗。
✅ 性能超越基準:邏輯推理、程式碼任務表現更勝傳統全注意力模型。
✅ 硬體友好設計:基於 GPU 特性優化,確保理論效率落地為實際速度。
一句話評價:NSA 以「省資源、省時間、強性能」三大優勢,重新定義大模型長文本處理的技術標準,極可能成為未來業界主流方案!
NSA的主要創新是什麼?
NSA(Natively Sparse Attention)的主要創新包括以下幾個方面:
- 動態層次稀疏策略:NSA結合了粗粒度的令牌壓縮和細粒度的令牌選擇,這樣可以在保持全局上下文感知的同時,提升局部精度。
- 硬體對齊的系統設計:NSA針對現代硬體進行了優化,特別是針對Tensor Core的利用和內存訪問,確保計算的算術強度平衡,從而實現更高的計算效率。
- 可訓練的稀疏性:NSA支持端到端的訓練,這意味著在訓練過程中可以有效地利用稀疏性,而不僅僅是在推理階段。這有助於減少預訓練計算,同時保持模型的性能。
- 三條注意力路徑:NSA通過三條平行的注意力路徑來處理輸入序列,包括壓縮的粗粒度令牌、選擇的重要令牌和滑動窗口以獲取局部上下文信息,從而提高了模型的效率和效果。
這些創新使NSA在長上下文建模中能夠實現更高的效率和性能,並且在多個基準測試中超越了全注意力模型。
NSA如何提高長上下文建模的效率?
NSA(Natively Sparse Attention)通過以下幾個方式提高長上下文建模的效率:
- 動態層次稀疏策略:NSA結合了粗粒度的令牌壓縮和細粒度的令牌選擇,這意味著在處理長序列時,模型能夠選擇性地計算關鍵的查詢-鍵對,從而顯著降低計算成本,同時保持上下文的完整性。
- 硬體優化:NSA的設計考慮了現代硬體的特性,例如Tensor Core的利用和內存訪問模式的優化,這樣可以減少內存瓶頸,提高計算速度,從而實現更快的推理和訓練過程。
- 三條注意力路徑:NSA通過三條平行的注意力路徑來處理輸入序列,包括壓縮的粗粒度令牌、選擇的重要令牌和滑動窗口來捕獲局部上下文信息。這種設計使得模型能夠在不同的上下文範圍內進行高效計算,提升了長上下文的處理能力。
- 可訓練的稀疏性:NSA支持端到端的訓練,這意味著模型在訓練過程中可以自動學習最優的稀疏模式,從而有效利用稀疏性,減少計算資源的消耗。
- 降低計算和內存需求:通過選擇性地計算和存儲關鍵的注意力權重,NSA減少了在長序列處理過程中所需的計算和內存需求,這有助於提升整體效率。
這些策略共同作用,使NSA在處理長上下文時能夠達到更高的計算效率和性能,從而在多種任務中表現優越。
NSA在訓練過程中如何支持端到端的計算?
NSA(Natively Sparse Attention)在訓練過程中支持端到端的計算主要通過以下幾個方面:
- 可訓練的稀疏性:NSA的設計使得稀疏性可以在訓練過程中進行學習,而不是僅在推理階段使用固定的稀疏模式。這意味著模型可以根據訓練數據自動調整其注意力模式,以獲得最佳性能。
- 平滑的計算圖:NSA的稀疏選擇過程是可微分的,這使得梯度能夠在訓練過程中流動。這樣,模型能夠學習到哪些令牌應該被選擇或壓縮,從而在整個訓練過程中優化其性能。
- 高效的反向傳播:NSA設計了高效的反向傳播機制,確保在選擇性計算的過程中不會引入計算瓶頸。這意味著在訓練過程中,模型能夠有效地更新權重,從而提高學習效率。
- 動態調整的注意力路徑:在訓練過程中,NSA根據當前的查詢動態構建壓縮的鍵和值表示,這使得模型能夠在不同的上下文中靈活調整其注意力機制,從而提高對長上下文的適應性。
- 整合多種注意力策略:NSA結合了壓縮、選擇和滑動窗口等多種注意力策略,這使得模型在訓練過程中能夠充分利用不同的上下文信息,從而提升整體性能。
這些特性使得NSA能夠在訓練過程中實現端到端的計算,從而減少了預訓練計算的需求,同時保持或提升模型的性能。
NSA相對於全注意力模型的速度提升有多大?
根據文獻中的實驗結果,NSA(Natively Sparse Attention)在處理64k長度序列時,相較於全注意力模型(Full Attention),在各個階段(解碼、前向傳播和反向傳播)都實現了顯著的速度提升。具體的速度提升比例如下:
- 解碼階段:NSA在解碼階段的速度提升達到約11.6倍。
- 前向傳播階段:在前向傳播過程中,NSA的速度提升約為9.0倍。
- 反向傳播階段:在反向傳播過程中,NSA的速度提升約為6.0倍。
這些數據顯示,NSA在處理長序列時能夠有效減少計算時間,從而提高整體運行效率,特別是在長上下文建模的應用中,這種速度提升是非常重要的。這表明NSA在保持模型性能的同時,能夠顯著提高計算效率。




