

Google Bard 正式對180個國家地區開放
新聞:Google Bard 即日開放並加入更多語言,新增影像、程式碼撰寫與應用整合功能 – 電腦王阿達
Google AI 聊天機器人 Bard 全面開放,支援英日韓文 | TechNews 科技新報
Google 2023 IO發表會 重點整理 懶人包|Google 摺疊機|Google Pixel Fold|Pixel 7a|AI|Bard| – YouTube
Google I/O重點整理!谷歌會是AI競爭的大贏家!Bard融合Adobe Firefly是種什麼樣的體驗!?🤖 – YouTube
解析》商戰絕佳範本!Google的AI大反攻 | 羅之盈 | 遠見雜誌
2023 Generative AI 年會
開放空間會議 百人交流會 共筆
https://gamma.app/docs/2023-Generative-AI–yk0du6uvt9i6hf3?mode=doc
- 活動大共筆:https://hackmd.io/@ejc/2023gaiconf
- 活動錄影回放購買意向調查表:https://forms.gle/HEGxMgESwop79Lmk7
- Google Docs 編輯版:https://bit.ly/44CZoG4
- 交流會來不及發的會後問卷有參加的人可以填一下:https://forms.gle/HqxNeZyKACJubnoL7
- 與 AI 對話:生成式 AI 在日常生活與工作中的新契機 By 薛良斌 / 布丁 / hlb
- AI圖像生成 創造動態的敘事創作 By 高捷
Meta AI : ImageBind:跨越六種模式的整體化AI學習
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
https://github.com/facebookresearch/ImageBind
新聞:Meta又開源AI模型,算盤打的是「AI元宇宙」!ImageBind如何帶來多感官體驗?
這篇文章主要講述了Meta(前Facebook)的最新開源AI研究項目「ImageBind」,以及該公司在AI領域的策略和挑戰。以下是文章的主要內容:
- Meta於2023年5月9日宣布了一個新的開源AI研究項目,名為「ImageBind」。這個模型不僅可以生成文字和圖片,還可以串聯起文本、聽覺、視覺數據、3D深度資訊、溫度、以及動作數據。這可能將是虛擬世界「元宇宙」計畫的一大步。
- Meta的AI研究部門定期發布公開的AI研究論文,與Google和OpenAI等公司形成對比。Meta的執行長馬克·祖克柏認為,公開研究成果可以讓Meta率先制定AI產品開發的行業標準,並讓外部開發者更好地融入Meta的生態系統。
- 儘管Meta在AI領域有著龐大的研究成果,但該公司的AI應用程式並不允許人們創建新內容,如文本或影像。這可能與Meta長期被控「散播仇恨言論、錯誤訊息」有關。
- Meta在AI開發方面面臨一些挑戰,包括硬體設備難以執行人工智慧系統的問題,以及在工具、工作流程和製程方面存在的差距。
- Meta的主要業務——銷售廣告,也是由AI來操盤的。在Instagram上看到的所有內容中,約有40%是由AI推薦的,而Instagram和Facebook兩個一起算的話,比率則是20%。
- Meta的研究部門與研究人員在今年2月開放了大型語言模型LLaMA給AI社群索取使用權限。雖然LLaMA的能力目前落後於OpenAI最新的GPT4模型以及Google的Bard,但開放資源仍然代表著AI研究社區不須強大的電腦,就可以修改底層程式碼。
這篇文章介紹了一種名為ImageBind的新型AI模型,這是首個能綁定來自六種模態的資訊的模型,這些模態包括文字、圖像/視頻、音訊、3D深度、紅外線熱度以及慣性測量單元(IMU)。ImageBind有助於機器更好地分析多種形式的資訊,並能優於先前為特定模式單獨訓練的模型。例如,利用ImageBind,Meta的Make-A-Scene可以從音訊創建圖像。此外,ImageBind也是Meta努力創建多模態AI系統的一部分,可讓機器從周遭所有可能的數據中學習。最後,透過將六種模態的嵌入對齊到一個共享空間,ImageBind能實現跨模態檢索、自然組合不同模態的語義,以及利用音訊嵌入生成圖像。

當人類從世界吸收信息時,我們天生使用多種感官,例如看到繁忙的街道和聽到汽車引擎的聲音。今天,我們介紹一種方法,使機器更接近人類同時、整體和直接從多種不同形式的信息中學習的能力,而無需明確的監督(組織和標記原始數據的過程)。我們已經建立並開源了 ImageBind,這是第一個能夠從六種模態中綁定信息的人工智能模型。該模型學習單一嵌入式或共享表示空間,不僅適用於文本、圖像/視頻和音頻,還適用於記錄深度(3D)、熱(紅外線輻射)和慣性測量單元(IMU)的傳感器,這些傳感器計算運動和位置。ImageBind為機器提供了全面的理解,將照片中的物體與它們的聲音、3D形狀、溫度以及運動方式相連接。
多模式學習的未來
憑藉使用多種輸入查詢模式並在其他模式中檢索輸出的能力,ImageBind 為創作者展示了新的可能性。想像一下,有人可以拍攝一個海洋日落的視頻,並立即添加完美的音頻剪輯以增強它,而一張虎斑狮子狗的圖像則可以產生有關類似狗的文章或深度模型。或者當像 Make-A-Video 這樣的模型製作了一個嘉年華的視頻時,ImageBind 可以建議背景噪音以配合它,創造出沉浸式的體驗。
人們甚至可以根據音頻來分割和識別圖像中的對象。這創造了獨特的機會,通過將靜態圖像與音頻提示結合起來創建動畫。例如,創作者可以將一張圖像與鬧鐘和公雞啼叫配對,並使用啼叫音頻提示來分割公雞或使用鬧鐘聲音來分割時鐘,並將它們都動畫化成視頻序列。
在我們目前的研究中,我們探索了六種模式,但我們相信引入盡可能多的聯繫感官的新模式,例如觸覺、語音、嗅覺和腦部 fMRI 信號,將使得更豐富的以人為中心的 AI 模型成為可能。
關於多模式學習仍有許多待揭示之處。人工智慧研究社群尚未有效量化僅出現在較大模型中的擴展行為並了解其應用。ImageBind 是朝向以嚴謹的方式評估它們並展示在圖像生成和檢索中的新應用的一步。
ChatGPT最後封印解除!預告將上線連網和外掛功能,Plus用戶下周可用免排隊
OpenAI 宣布將在下周向所有 ChatGPT Plus 使用者推出連網和外掛功能。OpenAI 表示,現在位於 Alpha 和 Beta 通道的 ChatGPT Plus 使用者,都能使用連網功能以及 70 多個已上線的外掛。
之前,OpenAI推出外掛功能立即就引起用戶的爆發性好評,使得ChatGPT可以使用工具、連網、運行計算的能力,不過當時需要申請加入候補名單才能使用。現在OpenAI將範圍擴大至所有ChatGPT Plus使用者。
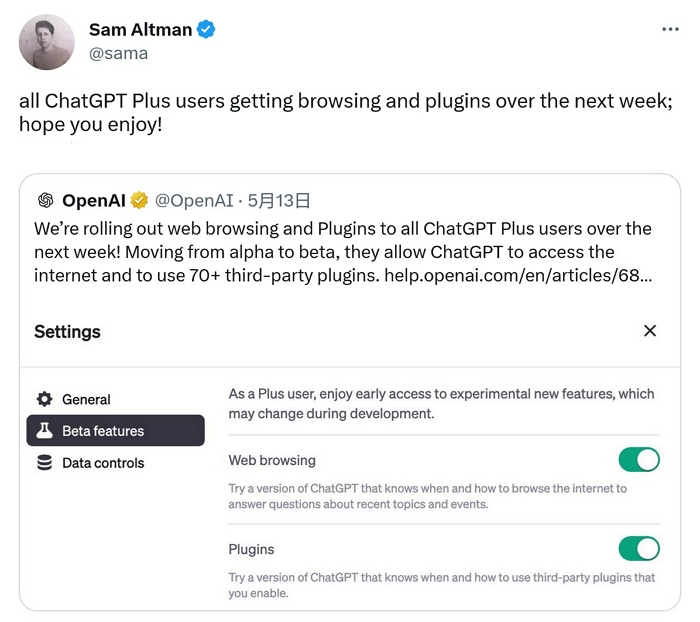
新聞來源:ChatGPT最後封印解除!預告將上線連網和外掛功能,Plus用戶下周可用免排隊 | T客邦




