

Github-Ranking
https://github.com/EvanLi/Github-Ranking/blob/master/Top100/Top-100-stars.md
Auto-GPT
https://github.com/Torantulino/Auto-GPT
Auto-GPT是一個開放源碼的實驗性應用程式,展示了GPT-4語言模型的能力。該程式由GPT-4驅動,將LLM“思想”鏈接在一起,以自主實現您設定的任何目標。作為GPT-4完全自主運行的最早示例之一,Auto-GPT推動了人工智能的可能性。該程式自由提供下載,但開發成本高昂,您可以透過贊助以援助開發。程式使用Python 3.8或更高版本以及OpenAI API和PINECONE API密鑰等技術。
AgentGPT
https://github.com/reworkd/AgentGPT
AgentGPT是一個允許用戶在瀏覽器內組裝、配置和部署自主AI代理的開源項目。它可以讓用戶為其設計一個自定義的AI,並使其達成任何目標。目前平台處於beta階段,正在加強長期記憶、web瀏覽和與人互動等功能的開發。該項目由Nextjs 13和Typescript等技術組成,並提供Docker和本地開發方式。項目運營需要贊助,支持者還可將其標誌放在下方展示,並可與創始人進行獨家對談。
GPT4All
https://github.com/nomic-ai/gpt4all
GPT4All是一個開源聊天機器人生態系統,其訓練集包括代碼、故事和對話等龐大且整潔的助理數據集。 GPT4All-J是其中一個模型,並且有官方Python和TypeScript綁定以及Web和聊天界面。該模型運行在M1 Mac上,並且可以在CPU和GPU界面上運行,以及在Atlas上整理數據集。此外,還有一些訓練GPT4All-J的技術報告和編譯器安裝程式。
gpt4all-j chat
https://github.com/nomic-ai/gpt4all-chat
gpt4all-chat是一個基於Qt的GUI專案,使用GPT-J作為基本模型。它是一個跨平台的UI界面,可在Linux、Windows、MacOSX三種平台上運行,支持更多功能,例如多種對話、語音轉文字、文字轉語音等。使用者也能夠輕鬆地安裝,支持各種桌面平台。此外,使用者還能夠自由開發自己的插件,以滿足更多的需求。該項目具有MIT許可證,可以免費使用,其中GPT4All-J模型採用Apache 2 License。
BabyAGI
https://github.com/yoheinakajima/babyagi
BabyAGI是一個以人工智能為基礎的任務管理系統,使用OpenAI和Pinecone APIs 創建、優先排序、執行任務。腳本使用OpenAI的自然語言處理功能創建新任務,使用Pinecone存儲和檢索任務結果。該腳本可以與所有OpenAI模型一起使用,可以通過命令行進行配置。BabyAGI由VC@yoheinakajima創建,是自動任務代理的簡化版本。應該負責任地使用腳本,以避免高API使用。
LangChain
https://github.com/hwchase17/langchain/
LangChain 是一個針對大型語言模型 (LLMs) 的應用程式開發套件,透過 Composability 的方式,讓使用者能將 LLMs 與其他運算或知識來源結合,開發更具有轉換性的應用程式。LangChain 提供了多個應用範例,包括問答、對話機器人、智能代理、記憶體、評估等方面。此外,LangChain 也提供完整的文件說明和開源程式碼,歡迎開發者加入貢獻。
LangChain是一個能夠協助使用大型語言模型(LLMs)構建應用程序並通過組合實現應用程序的庫。它提供了一種標准的接口,讓用戶可以使用多個數據源進行計算和知識的結合,並包括了問答、聊天機器人、代理人、記憶以及評估等幾個主要領域。LangChain的完整文檔包括:入門指南(安裝、環境設置、簡單示例),操作指南(演示、集成、輔助功能),API文檔以及核心概念解釋等。對於該領域,LangChain非常歡迎任何人的貢獻和參與。
https://python.langchain.com/en/latest/index.html
JARVIS
https://github.com/microsoft/JARVIS
JARVIS是一個協作系統,由一個LLM作為控制器和許多專家模型作為協作執行者組成。系統工作流程有四個階段:任務規劃、模型選擇、任務執行和響應生成。支援CLI、Web和Gradio等操作介面。JARVIS的主要應用是解決複雜的人工智能任務。更詳細的說明和程式碼下載網址可以參見他們的論文。
HuggingGPT:在 Hugging Face 中使用 ChatGPT 及其朋友解決 AI 任務
本文提出 HuggingGPT 框架,利用大型語言模型ChatGPT 與 Hugging Face共同解決複雜的 AI 任務,並認為語言是通用接口。HuggingGPT可涵蓋不同模態和領域的眾多 AI 任務,針對用戶請求進行任務規劃,選擇相應的AI模型並執行各子任務,總結回應。此框架不僅幫助人工智慧系統實現更加精細化的分工任務,還探索了不同 AI 技術之間的集成。
Hugging Face是人工智慧(AI)開源平台,共享超過10萬個預訓練模型、上萬資料庫。HuggingGPT是Hugging Face的新研究,聯合微軟和浙江大學推出全新協作系統,能讓開發者快速選擇合適的人工智慧模型,完成綜合文字、影片、語音等複雜任務。OpenAI則僅允許滿足條件的機構和個人進入,且產品費用高昂。Hugging Face希望每人都能做出生成式AI模型,包括各企業和普通開發者。
該文件討論了大型語言模型(LLMs)在使用語言作為通用界面解決複雜任務時,管理現有AI模型的潛力。為實現此目的,該文件提出了一個名為HuggingGPT的框架,它使用LLMs連接機器學習社區中的各種AI模型來解決AI任務。具體而言,HuggingGPT使用ChatGPT進行任務規劃,在Hugging Face中根據其功能描述選擇模型,執行每個子任務並根據執行結果對回答進行摘要。這種方法使得HuggingGPT能夠處理不同形式和領域中多個復雜的AI任務,在語言、視覺、語音和其他具有挑戰性的任務方面取得令人印象深刻的成果,實現可增長和可伸縮的AI能力。
介紹影片:微软JARVIS的原理解析:一个用ChatGPT和Hugging GPT连接的数千个AI模型的协作系统 – YouTube
### Summary
微軟的Jarvis項目是一個連接多個AI模型的系統,通過ChatGPT作為控制器和Hugging Face Hub中的專家模型協作執行任務。
### Highlights
– 🤖 Jarvis是微軟的AI項目,可以連接多個模型,實現複雜的任務。
– 📈 Jarvis使用ChatGPT和Hugging Face Hub的專家模型進行任務規劃、模型選擇、任務執行和回復生成。
– 🖼️ Jarvis可以用於圖像生成、描述和對象檢測等多個任務。

介紹影片:Hugging GPT贾维斯超级测评!通用人工智能AGI已来? – YouTube
介紹影片:强大的微软Jarvis(Hugging GPT + ChatGPT)操作教程 – 划时代意义的AGI技术 – 一键控制多AI 模型工作 – YouTube
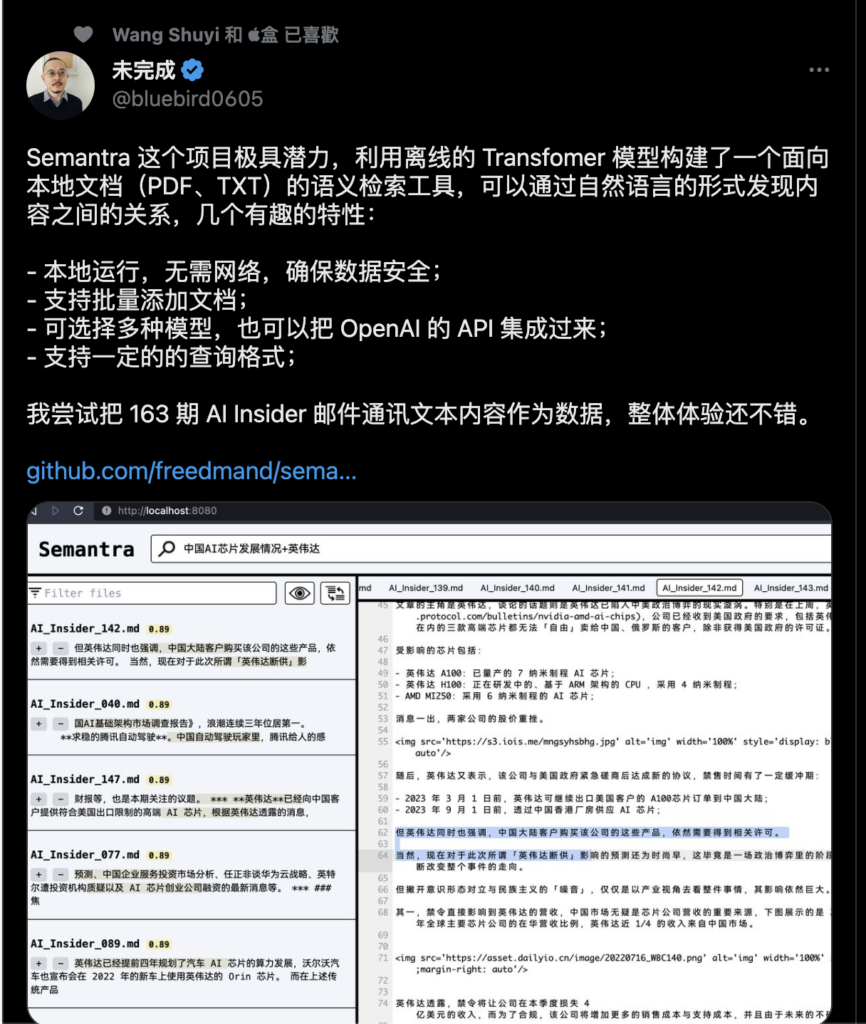
semantra
https://github.com/freedmand/semantra
Semantra 是一個用於語義搜尋文件的多功能工具,運行在命令行上,支持文本和PDF文件。它的目的是讓用戶方便地使用專業的語義搜尋引擎,並保證資料的私密性。Semantra 適用於各種用戶,如新聞記者、研究人員、學生和歷史學家等。使用此工具,您可以在本地電腦上互動式地進行語義查詢。
gpt4-pdf-chatbot-langchain GPT4和LangChain聊天機器人用於大型PDF文檔。
https://github.com/mayooear/gpt4-pdf-chatbot-langchain
教學影片:行动代号3000,让OpenAI帮你整理本地知识库,学习效率提升N倍! – YouTube
教學影片:GPT-4 & LangChain Tutorial: How to Chat With A 56-Page PDF Document (w/Pinecone) – YouTube
chatgpt-web
https://github.com/869413421/chatgpt-web
該項目是基於ChatGPT3.5 API實現的私有化web程序,支持定制化配置和參數設置。用戶可以根據自己的需求來定制化AI聊天機器人、產品名稱生成、python代碼修復器等二十多種參數,同時支持Markdown語法和提問上下文。使用前需要有openai賬號並創建好api_key。用戶可以通過直接下載二進制文件、基於源碼運行、使用docker運行等多種方式進行部署。
教學影片:本地私有化部署ChatGPT自己的AI小机器人 小白也能看懂的教程 – YouTube
https://github.com/Chanzhaoyu/chatgpt-web
用 Express 和 Vue3 搭建的 ChatGPT 演示網頁
介紹影片:Docker如何搭建属于自己的ChatGPT网站基于gpt-3.5-turbo – YouTube
介紹影片:ChatGPT接入到web网站保姆级教程 – 科技小飞哥
chatgpt-demo
https://github.com/anse-app/chatgpt-demo
Minimal UI for ChatGPT. ChatGPT 的極簡介面。
教學影片:无需服务器无需域名如何搭建自己的ChatGPT3 5网站 – YouTube
教學文章:無需服務器無需域名如何搭建自己的ChatGPT3.5網站
Stable.art
https://github.com/isekaidev/stable.art
Stable.art是一個針對Photoshop (v23.3.0+) 的開源插件,可以利用Automatic1111作為後端,使用Stable Diffusion加速藝術創作流程。該插件支持Lexica.art集成,還有txt2img、img2img/inpaint等功能,使用方法相對簡單,需要安裝CCX文件以及開啟API伺服器。如果你需要開發該插件,還需要安裝相關依賴。
介紹影片:開箱新體驗 04 – Stable Art 實測!Photoshop (PS)上直接生圖改圖 | Stable Diffusion API 教學 – YouTube
AudioGPT:理解和生成語音、音樂、聲音和說話頭部的技術
https://github.com/AIGC-Audio/AudioGPT
gpt4free
這篇文章介紹了一個叫做 gpt4free 的項目,它包含了多個反向工程的語言模型 API,旨在分散 AI 行業的中心化。文章描述了在開發過程中遭遇到了 OpenAI 的法律團隊的索賠,但沒有進一步的細節。文章還提供了一些用於使用和安裝 gpt4free 的指南,並列出了可用於該項目的多個 API 網站。此外,還提供了一些使用範例和其他待辦事項。該項目的版權屬於 GNU GPL v3。
https://github.com/xtekky/gpt4free
hlb/openai-examples
https://github.com/hlb/openai-examples
02 薛良斌 使用 GPT3 打造小工具 – YouTube
bark:文字生成更有感情、情緒的語音
文字提示生成音訊模型
https://github.com/suno-ai/bark
nanoGPT
Karpathy/nanoGPT是一個簡單,快速的庫,用於訓練/微調中型GPT模型。該代碼非常簡單,易於擴展和微調預先訓練的模型,並可以輕鬆地進行新模型的訓練。通過使用train.py和model.py文件,我們可以在OpenWebText上在單個8XA100 40GB節點上訓練GPT-2(124M)約4天。此外,本庫支持在不同的計算資源上進行快速和輕鬆的訓練,包括GPU和CPU。
https://github.com/karpathy/nanoGPT
DeepFloyd IF
IF 是一個由 DeepFloyd 創建的 Hugging Face 空間,其中包含社群成員製作的令人驚嘆的機器學習應用程式。使用者可以在 IF 中發現並評估這些應用程式,並將其應用於自己的項目中。IF 為機器學習社群提供了一個交流和學習的平台。
https://huggingface.co/spaces/DeepFloyd/IF
這是一個具有高度逼真度和語言理解能力的最新開源文本到圖像模型。DeepFloyd IF 是一個模塊化組成的模型,由一個凍結的文本編碼器和三個級聯的像素擴散模塊組成:一個基本模型,根據文本提示生成 64×64 像素的圖像,以及兩個超分辨率模型,每個模型都設計用於生成分辨率不斷增加的圖像:256×256 像素和 1024×1024 像素。模型的所有階段都利用基於 T5 變壓器的凍結文本編碼器來提取文本嵌入,然後將其餵入增強了交叉注意力和注意池的 UNet 架構中。結果是一個高效的模型,優於當前最先進的模型,在 COCO 數據集上實現了零樣本 FID 得分為 6.66。我們的工作強調了級聯擴散模型的第一階段中更大的 UNet 架構的潛力,並描繪了文本到圖像合成的有前途的未來。
https://github.com/deep-floyd/IF
bilingual_book_maker 雙語書籍製作者
bilingual_book_maker 是一個 AI 翻譯工具,使用 ChatGPT 幫助用戶製作多語言版本的 epub/txt/srt 文件和圖書。該工具僅適用於翻譯進入公共版權領域的 epub/txt 圖書,不適用於有版權的書籍。
https://github.com/yihong0618/bilingual_book_maker
介紹文章:從不自量力到AI 助力,我如何翻譯完一整本英文書- 少數派
Sigil是一個免費、開源、多平台的電子書編輯器,使用 Qt (和 QtWebEngine)。它設計用於編輯 ePub 格式的書籍(包括 ePub 2 和 ePub 3)。
Sigil 可以直接編輯EPUB 文件內含的HTML 格式,非常好用。
https://github.com/Sigil-Ebook/Sigil
Sigil官網:https://sigil-ebook.com/
MiniGPT-4
https://github.com/Vision-CAIR/MiniGPT-4
簡介:文章介紹了MiniGPT-4,它是一種預訓練的視覺-語言模型,可以生成與圖像相關的自然語言。 MiniGPT-4包括兩個訓練階段,第一個傳統的預訓練階段使用約500萬個圖像-文本對進行訓練,第二個調整階段使用人工創建的高質量圖像-文本對訓練模型,從而提高其生成能力和可用性。該模型已經在GitHub上公開發布,並且包括示範和教程。
應用:MiniGPT-4可用於生成與圖像相關的自然語言,例如圖像標註和視頻字幕。該模型可以在GitHub上下載,並包括使用示例和安裝指南。
最近的GPT-4展現了非凡的多模態能力,例如直接從手寫文字生成網站,以及識別圖像中的幽默元素。這些功能在以前的視覺語言模型中很少見。我們認為GPT-4具有先進的多模態生成能力的主要原因在於利用了更先進的大型語言模型(LLM)。為了研究這一現象,我們提出了MiniGPT-4,它將一個凍結的視覺編碼器與一個凍結的LLM(Vicuna)對齊,僅使用一個投影層。我們的研究發現,MiniGPT-4具有許多與GPT-4相似的能力,例如生成詳細的圖像描述和從手寫草稿創建網站。此外,我們還觀察到MiniGPT-4的其他新興能力,包括根據給定的圖像創作故事和詩歌,提供解決圖像中顯示的問題的解決方案,以及根據食物照片教用戶如何烹飪等。在我們的實驗中,我們發現僅對原始的圖像文本對進行預訓練可能會產生缺乏連貫性的不自然語言輸出,包括重複和片段化的句子。 為了解決這個問題,我們在第二階段精心挑選了一個高質量、良好對齊的數據集,使用對話模板來微調我們的模型。這一步驟對於增強模型的生成可靠性和整體可用性至關重要。值得注意的是,我們的模型高度計算效率,因為我們只訓練了一個投影層,利用了約500萬個對齊的圖像-文本對。
教學影片:【人工智能】全网独家首发 | 目前最完整MiniGPT-4本地安装部署中文教程 + 不完全避坑指南 | 开源版GPT-4 | 多模态图文识别和问答 – YouTube
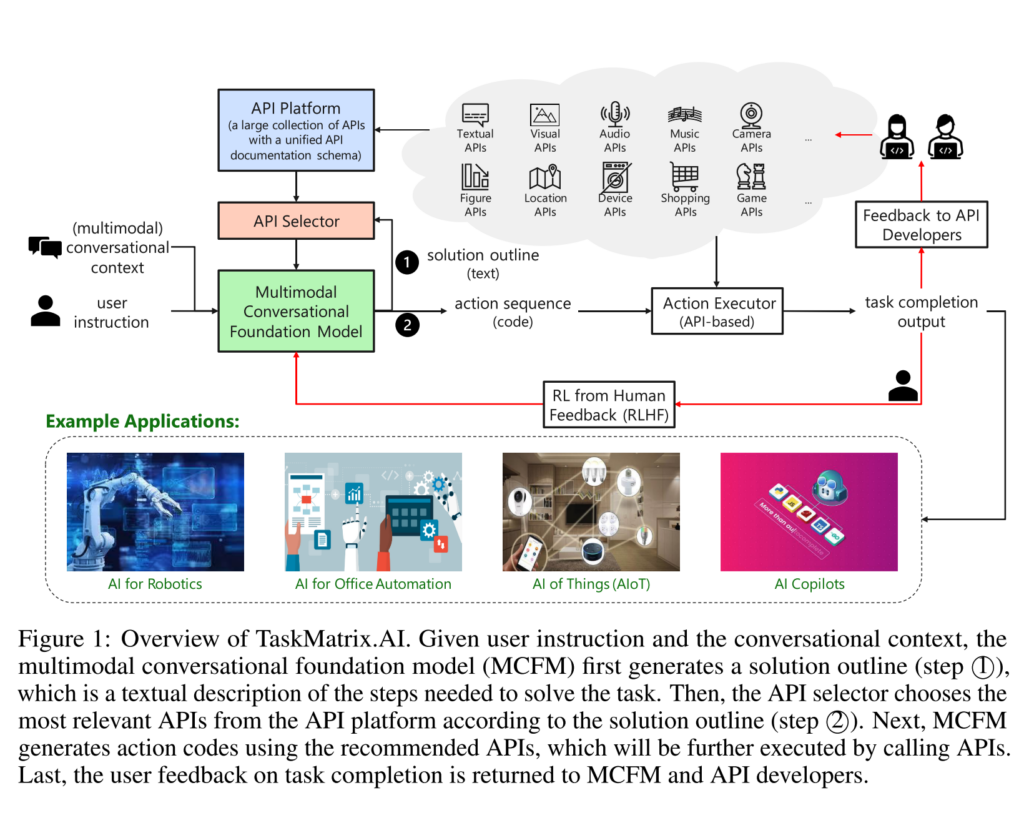
Microsoft TaskMatrix.AI:通過連接基礎模型和數百萬個API完成任務
https://github.com/microsoft/TaskMatrix
TaskMatrix.AI 是一個新的AI生態系統,它將基礎模型與數以百萬計的API連接起來以完成任務,實現神經和符號系統之間的順暢集成,具有強大的終身學習能力和可靠的性能。TaskMatrix.AI 的整體架構由四個關鍵組件組成:多模態對話基礎模型、API平台、動作執行器和對API開發者的反饋。TaskMatrix.AI 可以應用於不同的場景,包括AI驅動的內容創建、辦公自動化、現實世界的任務等等。
人工智慧(AI)近年來取得了驚人的進展。一方面,像ChatGPT這樣的先進基礎模型可以在廣泛的開放領域任務上提供強大的對話、上下文學習和代碼生成能力。它們還可以基於它們所獲得的常識知識為特定領域的任務生成高水平的解決方案概述。然而,它們在一些專門任務上仍然面臨困難,因為它們在預訓練期間缺乏足夠的領域特定數據,或者在那些需要精確執行的任務上,它們的神經網絡計算經常出現錯誤。另一方面,還有許多現有的模型和系統(基於符號或神經),可以非常好地完成一些特定領域的任務。然而,由於實現或工作機制的不同,它們不易於訪問或與基礎模型兼容。因此,迫切需要一種機制,可以利用基礎模型提出任務解決方案概述,然後自動匹配一些子任務到具有特殊功能的現成模型和系統,以完成它們。 受此啟發,我們推出了TaskMatrix.AI作為一個新的AI生態系統,將基礎模型與數百萬個API連接起來,以完成任務。與大多數旨在改進單個AI模型的先前工作不同,TaskMatrix.AI更注重使用現有的基礎模型(作為類似大腦的中央系統)和其他AI模型和系統的API(作為子任務求解器)來實現數字和物理領域的多樣化任務。作為一篇立場文件,我們將介紹如何建立這樣一個生態系統的願景,解釋每個關鍵組件,並使用研究案例來說明這個願景的可行性以及我們需要解決的主要挑戰。
論文網址:https://arxiv.org/pdf/2303.16434.pdf
介紹影片:【人工智能】解读微软Microsoft TaskMatrix.AI | 多模态对话基础模型MCFM + 海量API | 可能是大语言模型LLM的另一个未来发展方向 – YouTube
Summary
微軟發佈了一種新的機制TaskMatrix.AI,它將基礎的模型與數百萬個API連接起來,用來完成複雜的任務。它的主要優勢有四點:將基礎模型作為核心系統、提供統一的API平台、具有強大的終身學習的能力、以及更好的可解釋性。
Highlights
- 🤖 TaskMatrix.AI可以將基礎的模型與數百萬個API連接起來,用來完成複雜的任務。
- 🚀 它的主要優勢有四點:將基礎模型作為核心系統、提供統一的API平台、具有強大的終身學習的能力、以及更好的可解釋性。
- 💻 TaskMatrix.AI的架構包含四個主要的組成部分:多模態對話基礎模型MCFM、API平台、API選擇器和API執行器。它們共同工作來完成任務。
Jack-Cherish/PythonPark
Python 開源項目之「自學編程之路」,保姆級教程:AI實驗室、寶藏視頻、數據結構、學習指南、機器學習實戰、深度學習實戰、網絡爬蟲、大廠面經、程序人生、資源分享。
https://github.com/Jack-Cherish/PythonPark
Jack-Cui 崔
https://space.bilibili.com/331507846
Jack-Cherish/python-spider
Python3網絡爬蟲實戰:淘寶、京東、網易雲、B站、12306、抖音、筆趣閣、漫畫小說下載、音樂電影下載等
https://github.com/Jack-Cherish/python-spider
Jack-Cherish/Machine-Learning
機器學習實戰(Python3):kNN、決策樹、貝葉斯、邏輯回歸、SVM、線性回歸、樹回歸
https://github.com/Jack-Cherish/Machine-Learning
ShapE: Generating Conditional 3D Implicit Functions 根據文字或圖像生成3D物體。
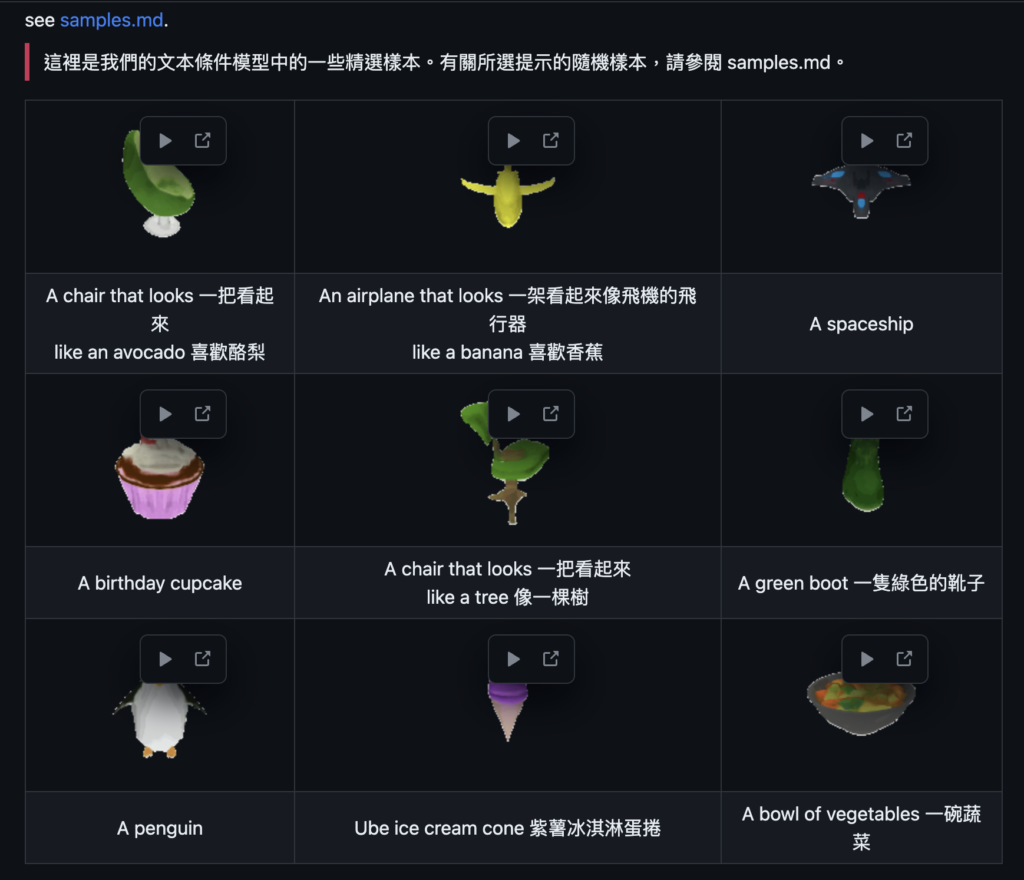
https://github.com/openai/shap-e
論文:[2305.02463] Shap-E: Generating Conditional 3D Implicit Functions
這份PDF文檔的主要內容是介紹一種名為ShapE的隱性擴散模型,該模型在3D隱性函數的空間上運行,可以被渲染為NeRFs和有紋理的網格。以下是文檔的幾個重點:
- ShapE模型與類似的顯性生成模型相比,給定相同的數據集、模型架構和訓練計算,ShapE的表現相當或超越。
- ShapE的純文本條件模型可以生成多樣化、有趣的對象,而不依賴於圖像作為中間表示。
- ShapE模型和PointE模型在訓練過程中的表現有所不同。在文本條件下,ShapE模型在訓練結束前的評估中表現變差,可能是由於對文本標題的過度擬合。而在圖像條件下,ShapE模型和PointE模型達到了大致相同的最終評估性能。
- ShapE模型和PointE模型在生成樣本時,儘管它們在不同的表示空間中產生樣本,但兩者的失敗案例相似,這表明訓練數據、模型架構和條件圖像比選擇的表示空間更影響結果樣本。
- ShapE模型與其他3D生成技術在CLIP R-Precision指標上的比較,優化基礎方法的樣本質量優於其他方法,但推理成本較高。
- 這些結果突顯了生成隱性表示的潛力,特別是在3D領域,它們比顯性表示提供更多的靈活性。
jerryjliu/llama_index LlamaIndex(GPT Index)是一個項目,提供一個中央介面,將您的 LLM 與外部數據連接起來。
https://github.com/jerryjliu/llama_index
AI唱歌:so-vits-svc 唱歌聲音轉換
SadTalker:學習逼真的三維運動係數,用於風格化音頻驅動的單張圖像說話臉部動畫。
https://github.com/OpenTalker/SadTalker
介紹影片:【AI唱歌】再次进化!6分钟学会用AI唱歌,杀疯了! – YouTube
DDSP-SVC:免費開源的AI變聲工具 – DDSP-SVC 3.0,低顯存運行,快速訓練模型,可替代SO-VITS-SVC
https://github.com/yxlllc/DDSP-SVC
DDSP-SVC是一個基於DDSP(Differentiable Digital Signal Processing)的即時端到端歌聲轉換系統。該系統可以在個人電腦上普及的免費AI語音變換軟體的開發。相較於著名的SO-VITS-SVC,該系統對於電腦硬體的要求更低,訓練時間可以大大縮短。同時,在進行實時語音轉換時,該系統的硬體資源消耗也更低,可以通過調整參數在相同的硬體配置下實現更低的延遲。
該系統的訓練步驟包括:預處理、訓練擴散模型(Diffusion Model)和訓練DDSP模型。該系統還提供了非實時推理和實時GUI界面的功能。
該系統使用的預訓練模型和配置文件需要事先下載和設置。訓練數據集需要放置在特定的目錄下,並且需要進行預處理。訓練過程可以使用TensorBoard進行可視化,同時還可以通過預設的預訓練聲碼器進行音頻增強。
該系統還支援多說話人訓練和語音合成。在實時語音轉換方面,系統提供了簡單的GUI界面,可以實現接近非實時合成的音質和低延遲的效果。
需要注意的是,使用該系統時應遵守法律法規,不要從事非法活動。系統的作者不對使用該系統造成的侵權、欺詐和其他非法行為負責。
詳細的安裝、配置和使用指南可以參考相應的文檔和說明。
以上是關於DDSP-SVC系統的內容摘要和重點介紹。
免费开源的AI变声工具 – DDSP-SVC 3.0整合包下载,低显存运行,快速训练模型,可替代SO-VITS-SVC – YouTube
Summary
- 🎙️ 免费开源的AI变声工具DDSP-SVC 3.0整合包下载,适用于低显存运行,快速训练模型,可替代SO-VITS-SVC。
- 🎛️ DDSP对硬件要求低,仅需2GB显存的显卡,训练时间为1到2小时。
- 🎵 DDSP 3.0版本通过浅扩散机制提升音质,效果接近SO-VITS。
Highlights
- 免费开源的AI变声工具DDSP-SVC 3.0整合包下载,适用于低显存运行,快速训练模型,可替代SO-VITS-SVC。DDSP对硬件要求低,仅需2GB显存的显卡,训练时间为1到2小时。
MockingBird (克隆聲音)
https://github.com/babysor/MockingBird
教學影片:AI工具 五秒声音克隆 mockingbird 支持中文 – YouTube
VITS-fast-fine-tuning (克隆聲音) 這個存儲庫是用於 VITS 微調的管道,以實現快速語音者適應 TTS 和多對多語音轉換。
https://github.com/Plachtaa/VITS-fast-fine-tuning
教學影片:【VITS在线训练】AI嘉然手把手教你使用VITS快速克隆任意角色声音_哔哩哔哩_bilibili
Drag GAN:智能拖拽式修圖
「Drag Your GAN Generative Image Manifold上的互動點基操控」是由Xingang Pan等人於SIGGRAPH 2023會議上發表的研究。該研究提出了DragGAN,一種互動式基於點的生成對抗網絡(GAN)操控方法。研究人員將於六月份釋出代碼。該方法可用於在生成圖像空間中進行直觀的操控和操作,並具有許多應用潛力。

https://github.com/XingangPan/DragGAN
論文:https://arxiv.org/pdf/2305.10973.pdf
介紹影片:AI修图技术步入新纪元 – DragGAN智能拖拽式修图,Leonardo, Stability更新,真假Midjourney中文版,人工智能新技术快报 – YouTube
bloomchat-SambaNova與Together聯合推出了類ChatGPT開源模型,有1760億參數,支持中文、英文、日文、法文、等46種語言;支持代碼生成,包括Python、java、php、cpp、Ruby、C++等13種編程語言
https://github.com/sambanova/bloomchat
此存儲庫包含 BLOOMChat 的數據準備、分詞、訓練和推理代碼。BLOOMChat 是基於 BLOOM 的 1760 億參數多語言聊天模型。
近日,SambaNova與Together聯合推出了類ChatGPT開源模型——BLOOMChat。BLOOMChat有1760億參數,支持中文、英文、日文、法文、等46種語言;支持代碼生成,包括Python、java、php、cpp、Ruby、C++等13種編程語言;可用於 Apache 2.0 修改版本下的研究和商業用例;知名開源平台持續提供技術迭代等。總之,BLOOMChat與目前市面上大多數類ChatGPT開源模型相比,在預訓練數據、指令調優、功能擴展、AI對齊等方面擁有巨大優勢。對於企業和個人開發者來說,無論用於商業化項目還是技術研究都是一個不錯的選擇。
sambanovasystems/BLOOMChat-176B-v1 · Hugging Face
在線體驗:https://huggingface.co/spaces/sambanovasystems/BLOOMChat
摘要
Together和SambaNova聯合推出了開源的ChatGPT模型BLOOMChat,具有1,760億參數,並支持46種語言,包括中文。該模型在預訓練數據、指令調優、功能擴展和AI對齊方面具有優勢。
亮點
- 💡 BLOOMChat模型支持中文等46種語言,參數數量龐大,且可商業使用。
- 💡 與其他開源模型相比,在預訓練數據、指令調優和功能擴展方面具有較大優勢。
- 💡 BLOOMChat在中文領域表現出色,對中文回答的邏輯和翻譯能力都非常出色。
簡要亮點
SambaNova和Together聯合推出的BLOOMChat是一個開源的ChatGPT模型,具有1,760億參數,支持中文和其他45種語言。與其他開源模型相比,在預訓練數據、指令調優、功能擴展和AI對齊方面具有優勢。BLOOMChat在中文領域表現出色,回答邏輯和翻譯能力都非常出色。
Voyager 是第一個使用大型語言模型(LLM)的具有開放式機體的終身學習代理程式,它在 Minecraft 中持續探索世界、獲得多樣技能並自主發現,不需要人類干預。
https://github.com/MineDojo/Voyager
官網:Voyager | An Open-Ended Embodied Agent with Large Language Models
問:VOYAGER 是什麼?
答:VOYAGER是第一款在Minecraft中使用LLM技術的具體化終身學習代理,可以持續探索世界、獲取多種技能並在無人干預下進行新的發現。
問:VOYAGER有哪三個主要組成部分?
答:1) 一個自動課程,用於最大化探索;2) 一個不斷增長的技能庫,用於存儲和檢索複雜行為;3) 一種新的迭代提示機制,結合環境反饋、執行錯誤和自我驗證來改進程序。
問:VOYAGER如何與GPT-4互動?
答:VOYAGER透過黑盒查詢與GPT-4互動,這避免了模型參數微調的需要。
問:VOYAGER開發的技能有什麼特點?
答:VOYAGER的技能具有時間延伸性、可解釋性和組成性,這迅速增強了代理的能力並減少了災難性的遺忘。
問:VOYAGER在Minecraft中的表現如何?
答:VOYAGER展示了強大的上下文終身學習能力,在玩Minecraft方面表現出色。相比之前的SOTA,它獲得了3.3倍更多的獨特物品,旅行了2.3倍的距離,並解鎖了技術樹里程碑,速度快達15.3倍。
問:在新的Minecraft世界中,VOYAGER的學習技能庫有何用途?
答:VOYAGER能夠在新的Minecraft世界中使用所學的技能庫從零開始解決新任務,而其他技術在推廣方面則遇到困難。
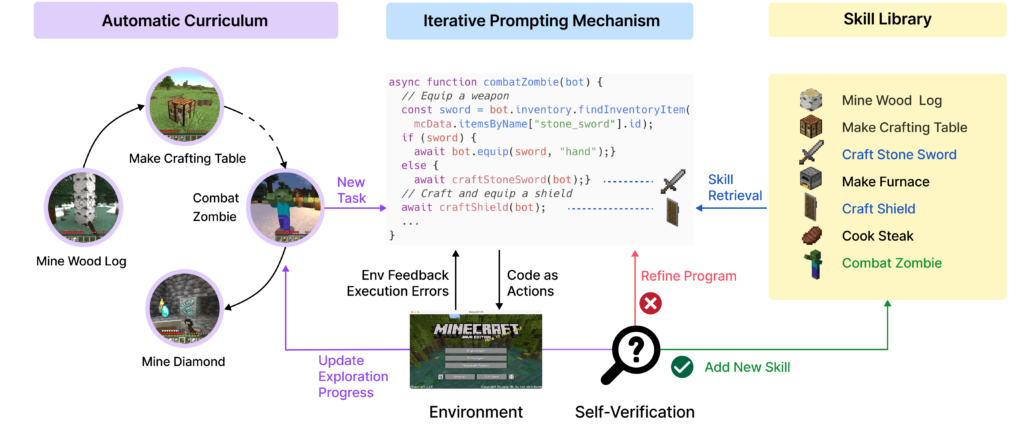
Voyager由三個關鍵組件組成:用於開放式探索的自動課程、用於越來越複雜行為的技能庫,以及使用代碼作為行動空間的迭代提示機制。
Voyager 包含三個關鍵組件:
1)最大化探索的自動課程設計,
2)可執行程式碼的不斷增長技能庫,用於存儲和擷取複雜行為,以及
3)新的迭代提示機制,包括環境反饋、執行錯誤和自我驗證,以改進程式。Voyager 通過黑盒查詢與 GPT-4 進行交互,無需進行模型參數微調。
Voyager 發展的技能具有時間延展性、可解釋性和組合性,可以快速提升代理程式的能力並減輕災難性遺忘。實驗結果顯示,Voyager 具有強大的內上下文終身學習能力,並在 Minecraft 遊戲中表現出色。它獲得的獨特物品數量增加了 3.3 倍,行進距離增加了 2.3 倍,並且解鎖關鍵技術樹里程碑的速度比先前最先進的方法快了多達 15.3 倍。Voyager 能夠在新的 Minecraft 世界中使用學到的技能庫從零開始解決新的任務,而其他技術往往難以泛化。
Voyager 的安裝需要 Python ≥ 3.9 和 Node.js ≥ 16.13.0,可以根據提供的指示進行安裝。安裝完成後,可以通過引入 Voyager 並使用相應的 API 密鑰來運行 Voyager。使用 Azure 登錄的話,還需要進行一些額外的設置和操作。
該項目僅用於研究目的,並非 NVIDIA 的官方產品。如果您認為我們的工作有用,請考慮引用相關文章。
介紹影片:【人工智能】全新AI智能体Voyager | 自己学会玩minecraft | 全场景终身学习 | 性能完胜AutoGPT | 英伟达Nvidia最新发布 | NPC取代人类玩家 – YouTube
### Summary
🎮 AI智能體Voyager在《我的世界》遊戲中展現了出色的終身學習能力和性能優勢。Voyager通過自學成才,掌握了遊戲中的生存技能,並能自主探索不同場景和任務。其使用GPT-4和迭代式構建的技能代碼庫,具備與人類玩家類似的能力。
### Highlights
– 🚀 AI智能體Voyager在《我的世界》遊戲中展現出卓越的性能和終身學習能力。
– 🎮 Voyager通過自主學習掌握了遊戲中的生存技能,並能進行全場景的探索。
– 🤖 Voyager使用GPT-4和迭代式構建的技能代碼庫,具備與人類玩家類似的能力,並在性能上超過了AutoGPT。
### Transcription
大家好,最近在遊戲領域的人工智能智能體又有了新的突破。英偉達的首席科學家Jim Fan等人將GPT-4引入了《我的世界》遊戲中,創造了一個全新的AI智能體,名為Voyager(航海家)。Voyager不僅在性能上勝過AutoGPT,還能夠在遊戲中進行全場景的終身學習。
Voyager通過自學成才,掌握了挖掘、建房屋、收集和打獵等基本的生存技能,並學會了自主進行開放式的探索。它可以前往不同的城市,經過海洋和金字塔,甚至可以自己搭建傳送門。通過不斷的探索和擴充,Voyager獲得了更多的物品和裝備,使用不同等級的盔甲並用柵欄來圈養動物。
在之前的AI領域中,構建具有通用能力的具身智能體一直是一個挑戰。傳統的強化學習和模仿學習方法在系統化的探索、可解釋性和泛化性方面往往表現不佳。然而,大語言模型的出現為構建具身智能體帶來了新的可能性。基於大語言模型的智能體可以利用預訓練模型中蘊含的世界知識生成一致的行動計劃或可執行的策略,非常適合應用於遊戲和機器人等任務。
Voyager的一個優勢在於它具備終身學習的能力。團隊通過使用GPT-4進行代碼執行的方式訓練Voyager,而不是使用傳統的梯度下降方法。訓練模型是以迭代方式構建的技能代碼庫,而不是簡單的浮點數矩陣。這種方法使得Voyager具備了類似於人類的終身學習能力。Voyager可以根據當前的技能水平和世界狀態來確定最合適的任務,並根據反饋不斷改進技能並保存在記憶中供下次調用。
Voyager的性能和終身學習能力與其他基於大語言模型的智能體進行了比較,包括ReAct、Reflexion和AutoGPT。在160次提示迭代中,Voyager發現了63個獨特的物品,比之前的方法多出了3.3倍。Voyager的自主探索驅使其進行廣泛的旅行,即使沒有明確的指示,Voyager也會遍歷更長的距離和訪問更多的地形。此外,Voyager在解鎖不同工具的速度上快於其他方法,例如木工具快了15.3倍,石工具快了8.5倍,鐵工具快了6.4倍。
這項研究的團隊來自英偉達、加州理工學院、德克薩斯大學奧斯汀分校和亞歷桑那州立大學。他們提出了三個關鍵組件:自動課程、技能代碼庫和迭代提示機制。自動課程根據智能體的技能水平和世界狀態提出合適的探索任務。技能代碼庫用於存儲和檢索複雜的行為,而迭代提示機制結合遊戲的反饋、執行錯誤和自我驗證來改進程序。
通過不斷創建自動的課程和完善技能庫,Voyager的能力不斷增強,就像一個永動機一樣,不停地探索新世界、學習新技能。團隊的實驗結果顯示,Voyager在解決各種任務上的速度和性能明顯優於其他方法,特別是與AutoGPT相比。技能庫的構建不僅提高了Voyager的性能,也提高了AutoGPT的性能,這證明技能庫作為一種通用工具可以有效地提高整體性能。
目前Voyager只支持文本,但未來也有可能通過視覺感知來進行增強。這項研究的開源代碼可以應用於其他領域,為自動生成任務、自動編寫代碼並保存可重用代碼庫提供了思路。對於有效的終身學習智能體來說,它應該具備根據當前技能和世界狀態提出合適任務的能力,通過環境反饋不斷完善技能並將其存入記憶中,同時持續探索世界以自我驅動的方式尋找新任務。
論文:https://arxiv.org/abs/2305.16291
這篇文章介紹了一種名為Voyager的新型態的大型語言模型(LLM)驅動的Minecraft遊戲代理人。以下是該文章的主要重點:
- Voyager的介紹:Voyager是第一個在Minecraft中持續探索世界、獲取多樣技能並進行新發現的LLM驅動的終身學習代理人,且不需要人類干預。
- Voyager的三個主要組成部分:
- 自動課程:最大化探索。
- 不斷增長的技能庫:用於儲存和檢索複雜行為的可執行代碼。
- 新的迭代提示機制:結合環境反饋、執行錯誤和自我驗證以改進程序。
- Voyager與GPT-4的互動:Voyager透過黑箱查詢與GPT-4互動,避免了模型參數微調的需求。
- Voyager的技能:Voyager開發的技能具有時間延長性、可解釋性和組合性,這加快了代理人能力的增長並緩解了災難性遺忘。
- Voyager的實證表現:Voyager展現了強大的情境終身學習能力,並在玩Minecraft時表現出異常的熟練度。它獲得了3.3倍更多的獨特物品,旅行了2.3倍更長的距離,並比先前的SOTA更快地達到了關鍵技術樹里程碑(高達15.3倍)。
- Voyager的應用:Voyager能夠在新的Minecraft世界中利用學習到的技能庫從零開始解決新的任務,而其他技術則難以推廣。
- 開源資源:作者在 https://voyager.minedojo.org/ 上開源了他們的完整代碼庫和提示。
privateGPT是一個使用GPT的工具,可以在沒有網路連接的情況下對文件進行提問,完全保護私隱,不會洩露任何數據。
它使用LangChain、GPT4All、LlamaCpp、Chroma和SentenceTransformers進行構建。使用者需要進行環境設置,安裝所需的依賴庫並下載LLM模型。該工具支援多種文件格式,並提供命令行界面和CLI參數進行操作。它通過本地的向量存儲庫和相似度搜索提供問答功能,完全在本地運行,不洩露數據。然而,這是一個測試項目,並不適用於生產環境。
quivr將所有文件和想法儲存在你的生成AI「第二大腦」中並與之交談
StanGirard/quivr: Dump all your files and thoughts into your GenerativeAI Second Brain and chat with it — StanGirard/quivr:將您的所有文件和想法傾倒到您的GenerativeAI Second Brain中,並與其聊天。 (github.com)
教學影片:如何用ChatGPT和你的卡片笔记对话? – YouTube 王樹義老師
Title StanGirard/quivr 將所有文件和想法儲存在你的生成AI「第二大腦」中並與之交談
Content Quivr是你的第二大腦,利用生成AI的力量來存儲和檢索非結構化信息。可以將其視為具有AI功能的Obsidian增強版。
重點特點:
-通用數據接受:Quivr能處理幾乎任何類型的數據,文字、圖像、代碼片段等都包括在內。
-生成AI:Quivr使用先進的AI來幫助生成和檢索信息。
-快速高效:設計迅速和高效,確保快速訪問數據。
-安全:你的數據,你掌控。始終保持安全。
-文件兼容性:文本、Markdown、PDF、Powerpoint、Excel、Word、音頻、視頻。
開放源碼:自由是美好的,Quivr也是如此。開源且免費使用。
演示重點:
-請注意:使用Streamlit的演示使用的是舊版本,新版本具有全新的用戶界面,但由於缺少舊版本的某些功能,尚未部署。預計在2023年5月25日之前上線。
-使用GPT3.5的演示:quivr-16.05.mp4
-Claude 100k內容的演示:https://github.com/StanGirard/quivr/assets/5101573/9dba918c-9032-4c8d-9eea-94336d2c8bd4
-新版本的演示(正在進行中):quivr-demo-new.mp4
入門指南:新版本 🚀
按照以下指示在本地機器上設置並運行該項目,用於開發和測試。
先決條件:
-確保已安裝以下內容:Docker、Docker Compose
此外,您還需要Supabase帳戶來:
-創建新的Supabase項目
-Supabase項目API金鑰
-Supabase項目URL
安裝步驟 💽
Step 0:如果需要,請在Youtube上查看安裝說明
Step 1:使用以下命令之一克隆存儲庫:
-如果您尚未設置SSH密鑰:git clone https://github.com/StanGirard/Quivr.git && cd Quivr
-如果您已經設置了SSH密鑰或者想要添加(指南在此):git clone [email protected]/Quivr.git && cd Quivr
Step 2:複製 .XXXXX_env 檔案
cp .backend_env.example backend/.env
cp .frontend_env.example frontend/.env
Step 3:更新 backend/.env 和 frontend/.env 文件
您的supabase_service_key可以在Supabase儀表板的項目設置-> API下找到。在項目API金鑰部分中使用匿名公共金鑰。
您的JWT_SECRET_KEY可以在Supabase設置的項目設置-> JWT設置-> JWT Secret下找到。
Step 4:通過Web界面上的Supabase數據庫運行以下遷移腳本(SQL編輯器->新查詢)
遷移腳本1
遷移腳本2
遷移腳本3
Step 5:啟動應用
docker compose build && docker compose up
Step 6:在瀏覽器中訪問localhost3000
貢獻者:
-感謝這些出色的人。
貢獻:
-有拉取請求嗎?打開它,我們將盡快審查。
-查看我們的專案看板,了解我們目前關注的事項,歡迎提出您的新思想!
路線圖、開放問題、拉取請求、初學問題、前端問題、後端問題等。
scholarphi 讓科學論文變得更容易理解
原始碼:https://github.com/allenai/scholarphi
論文:https://arxiv.org/abs/2009.14237
介紹影片:AI高效閱讀神器!全世界研究生有福了!【六指淵 Huber】 – YouTube
科學研究論文對於科學進步非常重要,但是閱讀這些論文可能會很困難,因為理解某些段落所需的資訊可能位於其他部分,或者甚至在另一篇論文中。因此,這篇論文提出了一種新的介面,名為ScholarPhi,可以在讀者最需要的時候和地方,提供技術術語和符號的定義。
ScholarPhi有四個新穎的特性:
- 工具提示:從論文的其他部分提供與位置相關的定義。
- 過濾器:可以”整理”論文,顯示出詞語或符號在論文中的使用情況。
- 自動方程圖:可以同時顯示多個定義。
- 自動生成的重要詞語和符號詞彙表。
透過使用者研究,發現這個工具能幫助所有經驗層次的研究者閱讀論文。此外,研究者們也希望在日常閱讀中能使用ScholarPhi的定義功能。
簡單來說,這篇論文的目標就是要讓科學論文變得更容易理解,透過提供一個新的閱讀介面,讓讀者在閱讀時能即時查詢到需要的定義和解釋。
Mr.-Ranedeer-AI-Tutor 一個可定制個性化學習體驗的 GPT-4 AI 導師提示。
https://github.com/JushBJJ/Mr.-Ranedeer-AI-Tutor
介紹影片:神奇的AI导师:如何使用 Mr. Ranedeer 的超强 Prompt 提示咒语,创建你的个性化学习计划 | 回到Axton – YouTube
摘要
這篇影片介紹了如何使用Mr. Ranedeer的超強Prompt提示咒語來創建個性化的學習計劃。Mr. Ranedeer是一個個性化的人工智能導師,通過配置選項可以為每個人定制專屬的教學計劃。影片中演示了如何使用JSON格式的Prompt進行配置,並展示了英語寫作和數學學習的例子。
亮點
- 🤖 Mr. Ranedeer是一個個性化的人工智能導師,可以根據配置選項為每個人定制專屬的教學計劃。
- 📝 使用JSON格式的Prompt可以方便地進行配置,創建個性化的學習計劃。
– 📚 影片中演示了如何通過Mr. Ranedeer學習英語寫作和數學,並展示了其詳細的學習計劃和內容可視化功能。
Mind-Video:電影式心靈風景:從腦部活動中高品質的視頻重建
Code:https://github.com/zjc062/mind-vis
本文介紹了MinD-Vis專案,該專案是用於從腦電記錄中解碼人類視覺刺激的框架。作者提出了一種名為MinD-Vis的方法,通過提取大規模靜息狀態功能性磁共振成像(fMRI)數據集中學習到的特徵表示的信息能力,可以僅使用少量配對註釋從腦電記錄中重建出高度逼真且具有語義匹配細節的圖像。實驗結果表明,該方法在語義映射(100類別語義分類)和生成質量(FID)方面優於現有方法,分別提高了66%和41%。
該專案的框架包括兩個主要階段:稀疏編碼腦模型(SC-MBM)和雙條件潛在擴散模型(DC-LDM)。文章提供了環境設置、數據下載和模型訓練等操作的詳細說明,並感謝Kamitani Lab、Weizmann Vision Lab和BOLD5000團隊提供數據支持,以及Facebook Research和CompVis提供的代碼和檢查點。
該研究論文被接受並發表在CVPR 2023會議上,並提供了相應的引用格式。
pythia:Transformers Across Time and Scale
EleutherAI的項目Pythia結合了可解釋性分析和縮放規律,旨在理解自回歸Transformer在訓練過程中知識的發展和演化。該項目提供了8個不同模型規模的套件,包括Pythia-70M、Pythia-160M、Pythia-410M、Pythia-1B、Pythia-1.4B、Pythia-2.8B、Pythia-6.9B和Pythia-12B。用戶可以通過Huggingface hub加載和使用這些模型。此外,該項目還提供了模型訓練的數據集、配置文件以及用於復現訓練過程的指南。
大型語言模型(LLMs)在訓練過程中是如何發展和演變的?隨著模型的擴大,這些模式會如何改變?為了回答這些問題,我們介紹了Pythia,一個包含16個LLM的套件,所有模型都在完全相同的順序下訓練於公共數據,模型大小範圍從70M到12B參數。我們為16個模型的每一個都提供了154個檢查點的公開訪問權限,並附帶了工具來下載和重建其確切的訓練數據加載器以進行進一步的研究。我們希望Pythia能促進許多領域的研究,並且我們提供了幾個案例研究,包括在記憶、短期效能上的詞頻效應和減少性別偏見方面的新結果。我們證明了這種高度控制的設置可以用來獲得有關LLMs和他們訓練動態的新見解。訓練模型、分析代碼、訓練代碼和訓練數據可以在 https://github.com/EleutherAI/pythia 找到。
Discord-AI-Chatbot 基於Python的Discord聊天機器人
這是一個基於Python的Discord聊天機器人,使用discord.py庫實現。它可以使用GPT回覆訊息,並利用Imaginepy生成圖片。機器人具有圖像OCR功能,可以從圖片中讀取文字,還可以使用DuckDuckGo進行網絡搜索,並為YouTube視頻提供詳細摘要。機器人還具有其他各種功能和命令,包括圖片生成、語音識別等。
https://github.com/mishalhossin/Discord-AI-Chatbot
CodeFormer:老照片救星!圖片解析度太低?照片拍攝太模糊?AI 一鍵提升畫質
https://github.com/sczhou/CodeFormer
《[NeurIPS 2022] 利用編碼本查詢Transformer實現魯棒盲目人臉修復》是一項關於人臉修復的研究工作。該專案使用了CodeFormer方法來進行人臉修復,並提供了對齊和修復人臉的功能。該專案還支援視頻輸入和人臉著色功能。使用該專案需要安裝PyTorch和其他必要的依賴項,並下載預訓練模型和測試數據。如果對研究有幫助,請引用作者的論文。該專案基於BasicSR,並採用了其他相關工作的代碼和方法。
該專案提供了對人臉進行修復的功能,包括對齊和修復人臉、整體圖像增強、視頻增強、人臉著色和人臉修補等。通過安裝依賴項、下載預訓練模型和測試數據,可以在本地運行該專案。該專案是基於CodeFormer方法進行研究的,並引用了其他相關工作。如有任何問題,請聯繫作者。
教學影片:老照片救星!圖片解析度太低?照片拍攝太模糊?AI 一鍵提升畫質!|Midjourney、Codeformer|泛科學院 – YouTube
Sudolang-是一種專為與AI語言模型(如ChatGPT、Bing Chat、Anthropic Claude和Google Bard)協同工作而設計的編程語言。
SudoLang 是一種專為與AI語言模型(如ChatGPT、Bing Chat、Anthropic Claude和Google Bard)協同工作而設計的編程語言。它易於學習和使用,並具有高度的表達力。SudoLang的特點包括自然語言約束編程、接口定義、/命令定義和引用全能等。相較於JavaScript或Python等編程語言,SudoLang更易學。此外,SudoLang還具有較高的表達性和緊湊性,可以縮短提示時間並提高響應速度。要了解更多有關SudoLang的信息,請閱讀相應文檔。

https://github.com/paralleldrive/sudolang-llm-support
影片:AI Driven Development with SudoLang – Autodux – YouTube
Open Interpreter
https://github.com/KillianLucas/open-interpreter
這是關於Open Interpreter的內容摘要: Open Interpreter是一個開源的本地運行工具,它讓語言模型能夠在你的電腦上運行代碼(包括Python、Javascript、Shell等)。你可以通過在終端中運行$ interpreter來像ChatGPT一樣使用它,它提供了自然語言接口,可以用於創建和編輯圖片、視頻、PDF等,控制Chrome瀏覽器進行研究,以及處理大型數據集等多種功能。 與ChatGPT的代碼解釋器相比,Open Interpreter在本地環境運行,具有更多的自由度和靈活性,可以訪問互聯網,無限制的運行時間和文件大小,以及使用任何包或庫的能力。 你可以通過命令行運行Open Interpreter,並根據需要配置不同的參數,還可以通過設置一個.env文件來自定義默認行為。但需要注意的是,由於生成的代碼在本地環境中運行,需要謹慎確認執行,以避免潛在的風險。 此外,Open Interpreter歡迎社區參與貢獻,並遵循MIT許可證。這個工具有助於使編程的好處更容易達到不同的受眾,提高了工作流程的效率。 希望這個簡要摘要有助於理解Open Interpreter的主要功能和特點。




